by Ashok Das
Another article in Ashok's series where he examines Oracle Data Integrator (ODI) Knowledge Modules (KM). For an basic introductory overview, check out 'What is an ODI Knowledge Module (KM)?'
Loading Knowledge Module (LKM)
The LKM is used to load data from a source datastore to staging tables. This loading comes into picture when some transformations take place in the staging area and the source datastore is on a different data server than in the staging area. The LKM is not required when all source datastores reside on the same data server as the staging area.
An interface consists of a set of declarative rules that define the loading of a datastore or a temporary target structure from one or more source datastores. The LKM executes the declarative rules on the source server and retrieves a single result set that it stores in a "C$" table in the staging area using defined loading method. An interface may require several LKMs when it uses datastores from heterogeneous sources.
LKM Loading Methods Are Classified as Follows
- Loading Using the Run-time Agent - This is a standard Java connectivity method (JDBC, JMS, etc.). It reads data from source using JDBC connector and writes to staging table using JDBC. This method is not suitable for loading large volume of data set as it reads data as row-by-row in an array from source and writes to staging as row-by-row in a batch.
- Loading File Using Loaders - This method is used to leverages most efficient loading utility available for the staging area technology (for e.g. Oracle’s SQL*Loader, Microsoft SQL Server bcp, Teradata FastLoad or MultiLoad) when the interface uses Flat file as a source.
- Loading Using Unload/Load - This is alternate solution for run-time agent when dealing with large volumes of data across heterogeneous sources. Data from sources can be extracted into flat file and then load the file into staging table.
- Loading Using RDBMS-Specific Strategies - This method leverages RDBMSs mechanism for data transfer across servers (e.g. Oracle’s database links, MS SQL Server’s linked servers, etc.)
A Typical LKM Loading Process Works in the Following Way
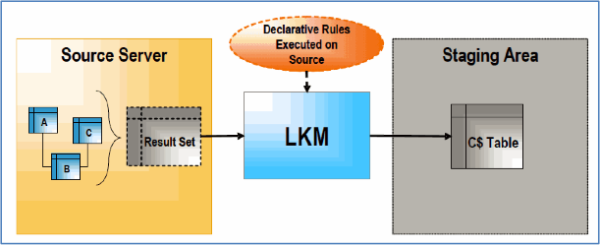
1. The loading process drops the temporary loading table C$ (if it exists) and then creates the loading table in the staging area. The loading table represents a source set i.e. the images of the columns that takes part in transformation and not the source datastore. It can be explained with a few examples below:
-
If only a few columns from a source table is used in a mapping and joins on the staging area, then loading table contains images of only those columns. Source columns which are not required in the rest of the integration flow will not appear in loading table.
-
If a source column is only used as a filter constraint to filter out certain rows and is not used afterward in interface, then loading table will not include this column.
- If two tables are joined in the source and the resulting source set is used in transformations in the staging area, then loading table will contain combined columns from both tables.
- If all the columns from a source datastore are mapped in interface and this datastore is not joined in source, then the loading table is an exact image of source datastore. For e.g. in case of a File as a source.
2. Data is loaded from the source (A, B, C in this case) into the loading table using an appropriate LKM loading method (run-time agent, RDBMS specific strategy).
3. Data from loading table is then used in the integration phase to load integration table.
4. After the integration phase, and before the interface completes, the temporary loading table is dropped.
LKM Naming Convention
LKM <source technology> to <target technology> [(loading method)]
Oracle Data Integrator provides a large number Loading Knowledge Modules out-of-the-box. List of supported LKMs can be found in ODI Studio and also can be seen in installation directory <ODI Home>\oracledi\xml-reference.
Below are examples of a few LKMs
|
Integration Knowledge Module |
Description |
|
LKM File to SQL |
Loads data from an ASCII or EBCDIC File to any ISO-92 compliant database. |
|
LKM File to MSSQL (BULK) |
Loads data from a file to a Microsoft SQL Server BULK INSERT SQL statement. |
|
LKM File to Oracle (EXTERNAL TABLE) |
Loads data from a file to an Oracle staging area using the EXTERNAL TABLE SQL Command. |
|
LKM MSSQL to MSSQL (LINKED SERVERS) |
Loads data from a Microsoft SQL Server to a Microsoft SQL Server database using Linked Servers mechanism. |
|
LKM MSSQL to Oracle (BCP SQLLDR) |
Loads data from a Microsoft SQL Server to Oracle database (staging area) using the BCP and SQL*Loader utilities. |
|
LKM Oracle BI to Oracle (DBLINK) |
Loads data from any Oracle BI physical layer to an Oracle target database using dblink. |
|
LKM Oracle to Oracle (datapump) |
Loads data from an Oracle source database to an Oracle staging area database using external tables in the datapump format. |
Integration Knowledge Module (IKM)
IKM takes place in the interface during an integration process to integrate data from source (in case of datastore exists in the same data server as the staging area) or loading table (i.e. C$ tables loaded by LKM in case of remote datastore on a separate data server than staging area) into the target datastore depending on selected integration mode; data might be inserted, updated or to capture slowly changing dimension.
ODI Supports the Integration Modes Below
- Append - Rows are append to target table. Existing records are not updated. It is possible to delete all rows before performing an insert by setting optional truncate property.
- Control Append - Does same operation as Append, but in addition data flow can be checked by setting flow control property. A flow control is used to check the data quality to ensure that all references are validated before loading into target.
- Incremental Update - Used for performing insert and update. Existing rows are updated and non-existence rows are inserted using Natural Key defined in interface, along with checking flow control.
- Slowly Changing Dimension - Used to maintain Type 2 SCD for slowly changing attributes.
IKM Integration Process Works in Two Ways
- When staging is on same server as target.
- When staging is on a different server than target (also referred as multi-technology IKMs).
1. When Staging is on the Same Data Server as Target
This is useful to perform complex integration strategies, recycling rejected records from previous runs, implementing technology specific optimized integration methods before loading data into target.
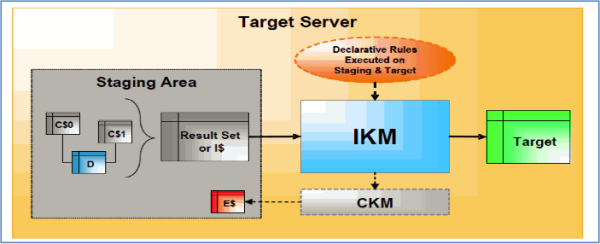
Typical Flow Process
- IKM executes a single set-oriented SQL based programming to perform staging area and target area declarative rules on all “C$” tables and source tables (D in this case) to generate result set.
- IKM then writes the result set directly into target table (in case of “Append” integration mode) and into an Integration table “I$” (in case of more complex integration mode. For e.g., Incremental Update, SCD) before loading into target. Integration table or flow table is an image of the target table with few extra fields required to carry out specific operations on data before loading data into target. Data in this table are flagged for insert/update, transformed and checked against constraint to identify invalid rows using CKM and load erroneous rows into “E$” table and removed them from “I$” table.
- IKM loads the records from “I$” table to target table using the defined integration mode (control append, Incremental update, etc.)
- After completion of data loading, IKM drops temporary integration tables.
- IKM can optionally call CKM to check the consistency of target datastore.
IKM can also be configured to recycle rejected records from previous runs from error table “E$” to integration table “I$” by setting property RECYCLE_ERRORS in the interface before calling CKM. This is useful for example when a fact or transaction rows that reference an INTEGRATION_ID of a dimension that may not exist in previous run of interface but is available in current run. So, the error record becomes valid and need to be reapplied to target.
2. When Staging is on a Different Data Server Than Target
This configuration is mainly used for data servers with no transformation capabilities and only simple integration modes are possible, for e.g. Server to File. CKM operations cannot be performed in this strategy.
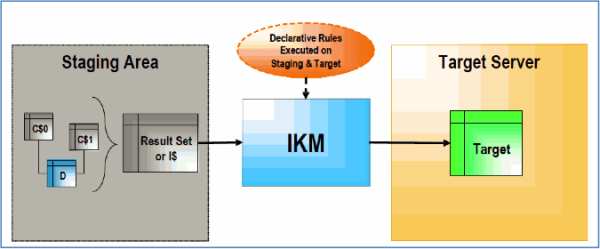
Typical Flow Process
- IKM executes a single set-oriented SQL based programming to perform staging area and target area declarative rules on all “C$” tables and source tables (D in this case) to generate result set.
- IKM then writes the result set directly into target table using defined integration mode (append or incremental update).
IKM Naming Convention
IKM [<staging technology>] <target technology> [<integration mode>] [(<integration method>)]
List of supported IKMs can be found in ODI Studio and also can be seen in installation directory <ODI Home>\oracledi\xml-reference.
Below Are Examples of a Few IKMs
|
Integration Knowledge Module |
Description |
|
IKM Oracle Incremental Update (MERGE) |
Integrates data into an Oracle target table in incremental update mode using the MERGE DML statement. Erroneous data can be isolated into an error table and can be recycled in next execution of interface. When using this module with a journalized source table, it is possible to synchronize deletions |
|
IKM Oracle Incremental Update |
Integrates data into an Oracle target table in incremental update. Erroneous data can be isolated into an error table and can be recycled in next execution of interface. When using this module with a journalized source table, it is possible to synchronize deletions |
|
IKM Oracle Slowly Changing Dimension |
Integrated data into Oracle target table by maintaining SCD type 2 history. Erroneous data can be isolated into an error table and can be recycled in next execution of interface. |
|
IKM Oracle Multi Table Insert |
Integrates data from one source into one to many Oracle target tables in append mode, using a multi-table insert statement. |
 |
Ashok Das is a Senior Consultant at KPI Partners and an Oracle Certified Specialist who specializes in OBIEE and the Oracle BI Applications. He has implemented BI Apps solutions for clients across various industries that include in Sales, Marketing, Supply Chain & Order Management, Financials, Projects, HR, and Procurement & Spend Analytics on source systems such as JDE, Salesforce, Siebel, Peoplesoft, and eBusiness. Check out Ashok's blog at KPIPartners.com. |


