by Ashok Das
Another article in Ashok's series where he examines Oracle Data Integrator (ODI) Knowledge Modules (KM). For an basic introductory overview, check out 'What is an ODI Knowledge Module (KM)?'
The Journalizing Knowledge Module (JKM) in Oracle Data Integrator (ODI)
Journalizing, commonly known as Change Data Capture (CDC), allows us to track changes that occur in data via inserts, updates or deletes. This enables a data transfomation tool, like Oracle Data Inetegrator (ODI), to load and process only changed or incremental data from a data source to a target. This eliminates processing of unchanged data during incremental loads which can significantly improve the performance of data extraction, transformation, and load processes.
Journalizing requires an infrastructure setup that can capture changes made to source records. Oracle Data Inetegrator (ODI) simplifies Change Data Capture (CDC) processes by providing pre-built functionality within "Knowledge Modules". These ODI Knowledge Modules leverage these Change Data Capture (CDC) mechanisms.
Unlike other Knowledge Modules which are used in Oracle Data Integrator (ODI) interfaces, Journalizing takes place within a model, sub model or in a datastore.

ODI Supports Two Types of Journalizing:
- Simple Journalizing
Tracks changes for each individual datastores in a model. Each journalized datastore is treated separately when capturing the changes. - Consistent Set Journalizing
Tracks changes to a group of datastores in a model, taking into account the referential integrity between the datastores. The group of datastores journalized in this mode is called a 'Consistent Set'.
The limitation of Simple Jounalizing is that referential integrity is not checked across datastores. For example, when employee information is extracted from PeopleSoft and from ADP Payroll, there is no guarantee that the newly captured insert data from ADP Payroll will have an associated record for an Employee in PeopleSoft.
As an alternate example with Consistent Set Journalizing, changes from ADP Payroll will be captured only when the associated PeopleSoft employee changes have been captured (and vice versa). It guarantees the consistency of the changes.
The set of available of changes for which consistency is guaranteed is called the Consistency Window. Changes in this window should be processed in the correct order by designing and sequencing the integration interfaces into packages (employee followed by payroll).
Although Consistent Set Journalizing is more powerful, it is also more difficult to set up. Consistent Set Journalizing should be used when referential integrity constraints need to be ensured when capturing the data changes, as in our example scenario. Consistent Set Journalizing is also recommended is also recommended when a large number of records are required and performance is a concern.
NOTE: It is not possible to journalize a model or datastores within a model using both Consistent Set Journalizing and Simple Journalizing.
Change Data Capture / Journalizing Infrastructure Components
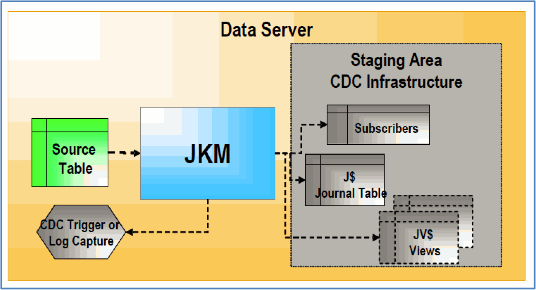
- Journals (J$)
This is where all changes are recorded. Journals contain references to the changed records along with the type of change (insert, update or delete).
- Capture Processes
Oracle Data Integrator (ODI) offers several options for Change Data Capture (CDC) in the source data:
- CDC using Oracle GoldenGate (OGG)
- CDC using Oracle Streams
- CDC using Database Triggers
- CDC using Data Server Log files (by reading the native iSeries Transaction Journals)
- Subscribers
Change Data Capture (CDC) uses a publish/subscribe model. Subscribers are entities (applications, integration processes, etc.) that utilize the tracked changes. Subscribers subscribe to a model's Change Data Capture (CDC) mechanism so the changes are tracked for them. Changes are captured only if there is at least one subscriber. When all subscribers have consumed the captured changes, these changes are discarded from the journals.
- Journalizing Views (JV$)
A Journalizing View provides access to the changes. These are used by users to view the captured changes and retrieve the changed data via integration processes.
- JKM Naming Convention
JKM <journalized technology> <journalizing mode> (<journalizing method>). Journalized technology refers to the technology into which changed data capture is activated. Journalized method is either Consistent Set Journalizing or Simple Journalizing. A list of supported Journalizing Knowledge Modules (JKMs) can be found in the Oracle Data Integrator (ODI) Studio. A list of supported Journalizing Knowledge Modules (JKMs) can also can be seen in installation directory <ODI Home>\oracledi\xml-reference.
[TABLE] Examples of Journalizing Knowledge Modules (JKMs):
|
Journalizing Knowledge Module |
Description |
|
JKM Oracle to Oracle Consistent (OGG) |
Creates and manages the ODI CDC framework infrastructure when using Oracle GoldenGate for CDC |
|
JKM Oracle 10g Consistent (Streams) |
Creates the journalizing infrastructure for consistent set journalizing on Oracle 10g tables, using Oracle Streams. |
|
JKM Oracle 11g Consistent (Streams) |
Creates the journalizing infrastructure for consistent set journalizing on Oracle 11g tables, using Oracle Streams. |
|
JKM Oracle Consistent |
Creates the journalizing infrastructure for consistent set journalizing on Oracle tables using triggers. |
|
JKM Oracle Consistent (Update Date) |
Creates the journalizing infrastructure for consistent set journalizing on Oracle tables using triggers based on a Last Update Date column on the source tables. |
|
JKM Oracle Simple |
Creates the journalizing infrastructure for simple journalizing on Oracle tables using triggers. |
The Service Knowledge Module (SKM) in Oracle Data Integrator (ODI)
A Service Knowledge Module (SKM) is in charge of creating and deploying data manipulation web services to a Service Oriented Architecture (SOA) infrastructure. These web services provide access to data in a datastore via a web interface. Web services also allows access to changed captured data for these datastores.
Service Knowledge Modules (SKM) are similar to Journalizing Knowledge Modules (JKM). But unlike other Oracle Data Integrator Knowledge Modules, SKMs do not generate executable code. Instead, SKMs generate Web Services Deployment Archive Files. SKMs are designed to generate Java code using Oracle Data Integrator's framework for Web Services. The Java code is then compiled and then eventually deployed on the Application Server's containers.
Web Services: Required Configuration & Components
Configuring the Web Service Containers
A web services container must be declared as a data server in the topology in order to let Oracle Data Integrator (ODI) deploy the web services upon iteslf. Configuration of a web services container depends on the type of web service container and the deployment mode.
ODI Supports Two Types of Web Service Container:
- JAX-WS, a Java API for XML web services. For e.g. Oracle WebLogic Server or IBM WebSphere.
- Apache Axis2, installed in an application server.
ODI Provides the Following Three Deployment Modes:
- Save Web Services Into Directory
The directory in which the web service will be created. It can be a network directory on the application server or a local directory when deploying web services separately into the container. - Upload Web Services by FTP
Uploads the generated web services to the container by FTP. - Upload Web Services With Axis2
Upload the generated web service to the container using Axis2 web service upload mechanism. This option appears only for Axis2 containers.
Setting Up the Data Sources
The Data Services generated by ODI do not contain connection information for sources and targets. Instead, it refers to data sources defined within the Web Services container or on the application server. These data sources contain connection properties required to access data, and must correspond to data servers already defined within the ODI topology.
A Data Source Can Be Configured Using One of the Following Options:
- Configure the data sources from the application server console.
- Deploy the data source from ODI if the container is an Oracle WebLogic Server.
Configuring the Model
To configure Data Services, you must first create and populate a model. Information about application server, data source name, data service name and service knowledge modules are specified in a model.
After configuration, next step is to generate and deploy the data services. Generating the data services for a model generates model-level services when the model is enabled for consistent set CDC and datastore-level services. Each generated data service offers a range of operations depending on the SKMs used to generate it.
The Following Services are Available at Model-Level:
- Extend Window (no parameters)
Carries out an extend window operation. - Lock (Subscriber Name)
Locks the consistent set for the named subscriber. To lock the consistent set for several subscribers, call the service several times. - Unlock (Subscriber Name)
Unlocks the consistent set for the named subscriber. - Purge (no parameters)
Purges consumed changes.
The Following Operations are Available at Datastore-Level:
- Operations on a Single Entity
These operations allow a single record to be manipulated, by specifying a value for its primary key. Other fields may have to be supplied to describe the new row, if any. Examples: addcustomer, getcustomer, deletecustomer, updatecustomer. - Operations on a Group of Entities Specified by Filter
These operations involve specifying values for one or several fields to define a filter, then optionally supplying other values for the changes to be made to those rows. In general, a maximum number of rows to return can also be specified. Examples: getcustomerfilter, deletecustomerfilter, updatecustomerfilter. - Operations on a List of Entities
This list is constructed by supplying several individual entities, as described in the "single entity" case above. Examples: addcustomerlist, deletecustomerlist, getcustomerlist, updatecustomerlist.
Service Knowledge Module (SKM) Naming Convention
SKM <Data server technology>
Data server technology is the technology into which the data to be accessed with web services is stored.
List of supported SKMs can be found in ODI Studio and also can be seen in installation directory <ODI Home>\oracledi\xml-reference.
Below are Examples of a Few SKMs:
|
Service Knowledge Module |
Description |
|
SKM Oracle |
Generates data access Web services for Oracle databases. |
|
SKM Informix |
Generates data access Web services for IBM Informix databases. |
|
SKM IBM UDB |
Generates data access Web services for IBM DB2 UDB databases. |
|
SKM HSQL |
Generates data access Web services for Hypersonic SQL databases. |
|
SKM SQL |
Generates data access Web services for ANSI SQL-92 compliant databases. Data access services include data manipulation operations such as adding, removing, updating or filtering records as well as changed data capture operations such as retrieving changed data. Data manipulation operations are subject to integrity check as defined by the constraints of source datastores. Consider using this SKM if you plan to generate and deploy data manipulation or changed data capture web services to your Service Oriented Architecture infrastructure. Use specific SKMs instead, if available for your database. |

 |
Ashok Das is a Senior Consultant at KPI Partners and an Oracle Certified Specialist who specializes in OBIEE and the Oracle BI Applications. He has implemented BI Apps solutions for clients across various industries that include in Sales, Marketing, Supply Chain & Order Management, Financials, Projects, HR, and Procurement & Spend Analytics on source systems such as JDE, Salesforce, Siebel, Peoplesoft, and eBusiness. Check out Ashok's blog at KPIPartners.com. |



