

How does Synapse Analytics improve over Azure SQL DW Gen 2 and Gen 1
Introduction
If you are not familiar with Synapse Analytics (formerly Microsoft Azure SQL Data Warehouse), it is known as a massively parallel processing system (MPP). MPP systems have been around for a long time, but traditionally they have been very expensive and large hardware investments. Some providers in this space include Teradata, Netezza, and Microsoft, with their analysis platform system offer. In this model, the data in the tables is distributed between the nodes and the results are joined in the main or control node. It is a model that is fully optimized for large-scale data loading, as well as for reports.
As you know, data warehouses are divided into fact and dimension tables. Fact tables are commonly generated in a transactional system (think of the point of sale) and then loaded into the data warehouse. Dimension tables contain attributes such as dates or product names. These may change infrequently and are usually much smaller than fact tables.
In Synapse, fact tables are distributed between nodes using a hash column, while smaller dimensions are replicated across all nodes, and larger dimensions use the same hash distribution. The objective of this is to minimize the movement of data between nodes; While it is extremely fast, reading data from the nodes, having to perform cross-node look-ups is very expensive, so the designs usually aim to minimize this.
Synapse allows you to quickly deploy a high-performance cloud data warehouse, available worldwide, and secure. You can independently scale computing and storage while pausing and resuming your data warehouse in minutes through a massively parallel processing architecture designed for the cloud. It offers a guaranteed availability of 99.9 percent.
What Azure Synapse Analytics Adds New to the Table
With Azure Synapse Analytics, Microsoft makes up for some missing functionalities in Azure DW or generally the Azure Cloud overall. Synapse is thus more than a pure rebranding.
On-Demand Queries
With Synapse, we can finally run on-demand SQL or Spark queries. Rather than spinning up a Spark service (e.g., Databricks) or resuming a Data Warehouse for running query, we can now write our SQL or PySpark code and pay per query. On-demand queries make it so much easier for analysts to take a quick look at a .parquet file (just opening it in Synapse - see example below) or to analyse the Data Lake for some interesting data (using the integrated Data Catalog)
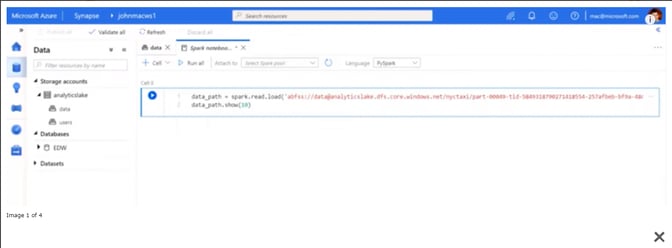
Opening a Data Lake parquet file directly in a Notebook
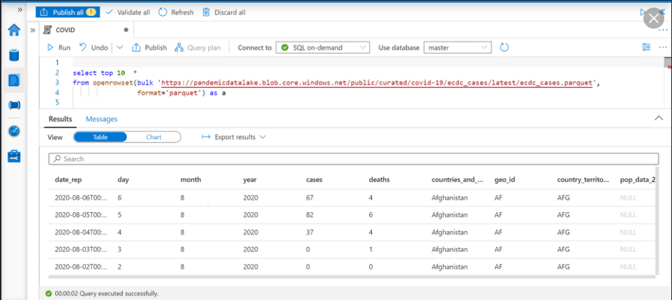
SQL On Demand
Integration of Storage Explorer
Data in your data lake isn't always easy to browse through, and it�s for sure not easy for a business user or analyst. Within Synapse, Azure now integrated their Storage Explorer interface: a way to easily browse through the Data Lake and access all folders.
With Data Explorer integrated, an analyst can - in one interface - see and access all the data in the Data Lake and Data Warehouse (which he/she has access to): no further connection strings to be created and shared and no need for local tool such as SQL Server Management Studio (for accessing the Data Warehouse) and Azure Storage Explorer for Data Lake browsing.
Notebooks and SQL Workbench
Up to now, analysts or data scientists had to work with local notebook tools (Jupyter), Databricks and/or local SQL tools to access the different data from the Data Lake or Data Warehouse. Both Azure Data Warehouse and Data Lake Store had data explorer in preview, but the functionalities where limited.
Within Synapse, Microsoft has introduced an end-to-end analysis workbench accessible from web-UI/portal. One can write SQL Queries and execute them on SQL Pools(Datawarehouse compute), On-Demand SQL or Spark Compute.
SQL Analytics on Data Lake
Parquet-format is a great highly-compressed format commonly used in Data Lakes. It's great to store but a bit more cumbersome to read and analyze: you can't open a parquet file in Windows; you'll need a tool that can read parquet.
Within Synapse, Microsoft integrated SQL Analytics functionalities on Data Lake formats: you can now run SQL script on parquet files directly in your Data Lake: e.g., using right-click on the files and using 'Open in SQL Script.
Synapse (Formerly Azure SQL Data Warehouse Gen2) Over Gen1
There have been constant improvements in Azure SQL Data Warehouse performance since the product was introduced. The first was to move from standard Azure storage to premium (SSD), which happened quite early in the service life cycle.
In May, 2018, Microsoft announced Gen2 of the hardware for the product -- the "Compute Optimized" tier, which includes caching data to super-fast local NVMe drives while still storing the larger volume of data on networked premium storage. This allows the service to deliver up to 2GB per second of local I/O bandwidth, and up to 5x query performance improvements.
SQL Data Warehouse adapts to your workload through smart caching to accelerate data access and query performance to handle the most demanding data storage workloads. Create your analysis center seamlessly together with native connectivity with data integration and visualization services, all while using your existing SQL and BI skills.
Gen2 is generally available in 20 Azure regions and offers below benefits:
- Improves individual query execution times by as much as ten times over the Gen1 tier
- Provisions SQL Data Warehouse with five times the computing power and unlimited storage capacity, making it suitable for the most intensive analytics workloads
- Uses the latest generation of Azure hardware to improve compute and storage scalability
- The service levels for Gen1 range from DW100 to DW6000, where as Gen2 provides 5xmore memory per query than the Gen1. This extra memory helps the Gen2 deliver its fast performance. The performance levels for the Gen2 range from DW100c to DW30000c.
- The maximum Gen2 DWU is DW30000c, which has 60Compute nodes and one distribution per Compute node. For example, a 600 TB data warehouse at DW30000c processes approximately 10 TB per Compute node.
- To ensure each query has enough resources to execute efficiently, SQL Data Warehouse tracks resource utilization by assigning concurrency slots to each query. The system puts queries into a queue based on importance and concurrency slots. Queries wait in the queue until enough concurrency slots are available.
- The smallrc resource class on Gen1allocates a fixed amount of memory per query, similar in fashion to the static resource class staticrc10, Because smallrc is static, it has the ability to scale to 128 concurrent queries, whereas the smallrc resource class on Gen2 dynamically adds memory as the service level increases and only supports a max 32 concurrent queries at DW1000c and four and DW100c Once the instance is scaled beyond DW1500c, the concurrency slots and memory used by smallrc increases as the service level increases.
- Geo-backups are on by default. If your data warehouse is Gen1, you can opt out if you wish. You cannot opt out of geo-backups for Gen2 as data protection is a built-in guaranteed.
On Gen1
- Smallrc queries do not dynamically get more memory as the service level is increased.
- As service levels change, the available query concurrency can go up or down.
- Scaling service levels does not provide a proportional change to the memory allocated to the same resource classes.
On Gen2
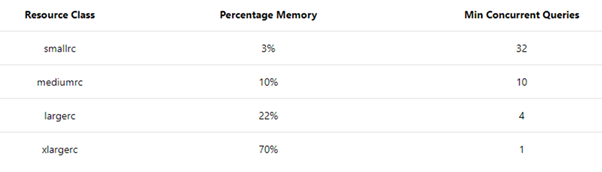
The dynamic resource classes are really dynamic and address the points mentioned above. The new rule is 3-10-22-70 for percentage memory allocations for small-medium-large-xlarge resource classes, regardless of service level. The following table contains the consolidated details of the percentages of memory allocation and the minimum number of concurrent queries that are executed, regardless of service level.
Well, that's its folks. Please watch this section for more exciting posts on Azure Synapse Analytics.
As a Microsoft Azure partner, KPI Partners can help you with consulting, mentoring, and training services for Microsoft Data Management, Business Intelligence, and Analytics. Let us contact you.




Comments
Comments not added yet!