

by Santoshkumar Lakkanagaon
Modern Big Data requirements include:
- Multi-region availability
- Fast and reliable response
- No single point of failure
- Scalability
Traditional relational databases (RDBMS) are not enough to meet these requirements because the relational model provides normalized schema, table joins and ACID compliance which causes a massive overhead for big data. In order to support these features, we need high-end systems which are not cost effective. Additionally, such systems often require substantial downtime.
So, how do we come overcome these challenges? We need a few strategies to manage Big Data, some of which are listed below:
- Distribute data across nodes
- Relax consistency requirements
- Relax schema requirements
- Optimize data to suit actual needs
This is where non-relational databases also known as NoSQL databases are useful.
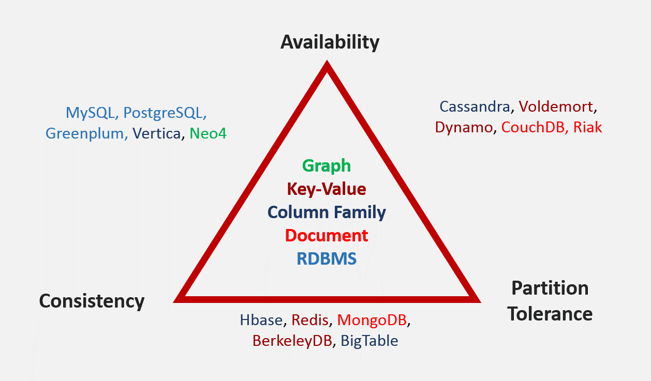
There are four broad classes of NoSQL databases:
- Graph: data elements each relate to others in a graph or network (e.g. Neo4j)
- Key-Value: keys map to arbitrary values of any data type (e.g. Dynamo, Voldemort, Redis, BerkeleyDB)
- Document: document sets (JSON) allow queries in whole or part (e.g. MongoDB, CouchDB, Riak)
- Column Family: keys mapped to sets of n-number of typed columns (e.g. Cassandra, HBase BigTable, Vertica)
There are three important factors which help navigate the NoSQL landscape:
- Consistency: do you get identical results, regardless of which node is queried?
- Availability: can the cluster respond to very high write and read volumes?
- Partition Tolerance: is the cluster still available when part of it goes dark?
What is the CAP theorem?
In distributed systems, consistency, availability, and partition tolerance exist in a mutually dependent relationship. This means that we can't achieve all three properties in one NoSQL database, we have to sacrifice one property.
As this blog is specific to Apache Cassandra, we will go through what is Cassandra, its architecture, benefits, and use cases.
What is Apache Cassandra?
Cassandra is a top level Apache project, it is an Open Source, fully distributed, linearly scalable storage system for managing large amount of data spread across the world with no single point of failure.
Cassandra is built using two core technologies:
- Google Big Table: This is the foundation for the storage model
- Amazon Dynamo: This is foundation for the distribution model
Facebook integrated these two technologies and released it as Cassandra.
Cassandra belongs to the column family type of NoSQL database it picks availability and partition tolerance from the CAP properties. However, one of the stronger features of Cassandra is its ability to utilize tuneable consistency.
Now, let's understand a few terminologies in Cassandra:
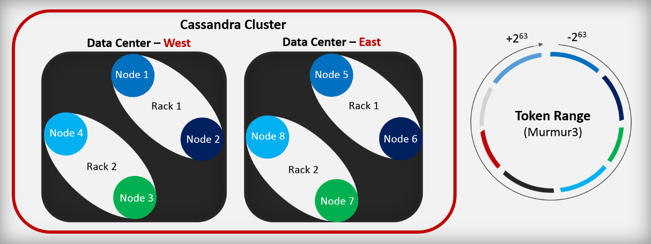
- Node: one Cassandra instance
- Rack: a logical set of nodes
- Data Center: a logical set of racks
- Cluster: the full set of nodes which map to a single complete token ring
- Coordinator: the node chosen by the client to receive a particular read or write request to its cluster
- Replication Factor: onto how many nodes should a write be copied? It is set at the table level.
- Consistency Level: how many nodes must acknowledge a read or write request? It is set before issuing the query.
- Partition Key: the primary key or part of the primary key of the Cassandra table
- Token: Cassandra uses the partition key of a record and hashes using mumur3 partitioning algorithm and gives an integer value called token
- Token Range: Each node is associated with a token or range of tokens called as token range. Token range is usually between +2^63 to -2^63.
- CQL: Cassandra Query Language is used to model data in Cassandra and handle read and write requests
- Virtual Node (Vnode): a node which owns multiple token range segments instead of one large range
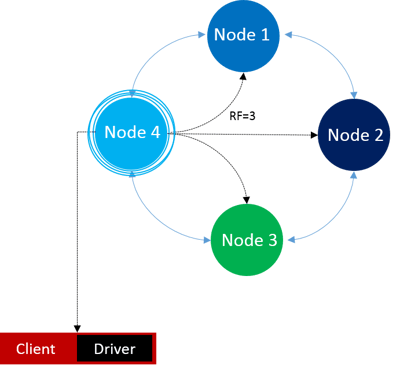
How are Write requests handled in Cassandra?
First, the Cassandra driver chooses a coordinator for a write request, then it hashes partition keys and generates tokens for each partition. Next, it sends the data to corresponding node which owns this token value. If the replication factor (RF) is greater than one (let's say two), then it sends a copy of the data to the nearest node, similarly for RF = 3 and so on.
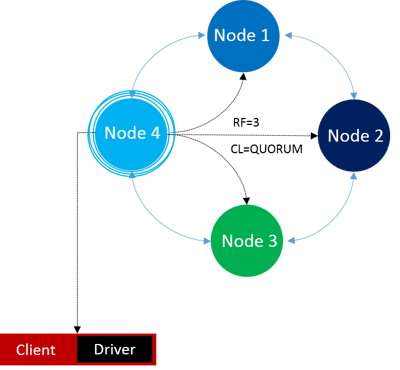
How are Read requests handled in Cassandra?
Similarly, the Cassandra driver first identifies a coordinator, then gets all the replications from the original and copied nodes, hashes the data received from replicated nodes and compares the hash values based on set consistency level (CL). If the CL is set to one, then it just sends out whichever node has the latest data, if it is two then it compares two copies. It returns data only if the values match else an error message is displayed. If the CL is set to Quorum which is nothing but (RF/2) + 1 (for example if RF = 3, then CL will be 3 according to the formula).
How are Write and Read requests handled if a node fails or goes down?
Write requests run on the Hinted Handoff mechanism a recovery mechanism for writes targeting offline nodes. In this mechanism, a coordinator node stores the data if the target node for a write is down or fails to acknowledge. Backed up data in a coordinator is rewritten when the target node comes online within a specified amount of time.
Read requests depend on the RF and CL values if CL < RF, it returns the data by comparing with other replicated nodes and if CL = RF then it displays an error message.
What is a Column Family?
As mentioned already, it is keys mapped to sets of 'n' number of typed columns.
- Rows individual rows constitute a column family
- Row key uniquely identifies a row in a column family
- Row stores pairs of column keys and column values
- Column key uniquely identifies a column value in a row
- Column value stores one value or a collection of values
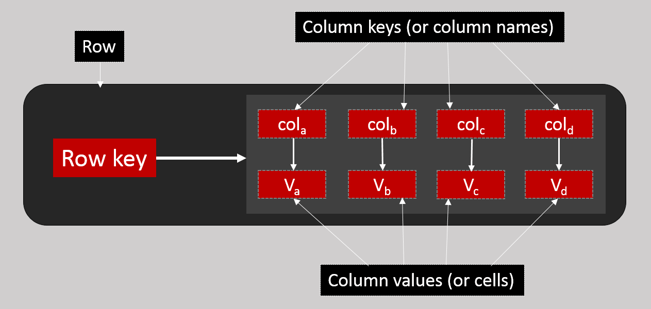
Note: Column Family terminologies (Thrift API terms) are used for Cassandra 1.1 and its previous versions
What is a CQL table?
CQL table provides two dimensional views of a column family containing potentially multi-dimensional data due to composite keys and collections.
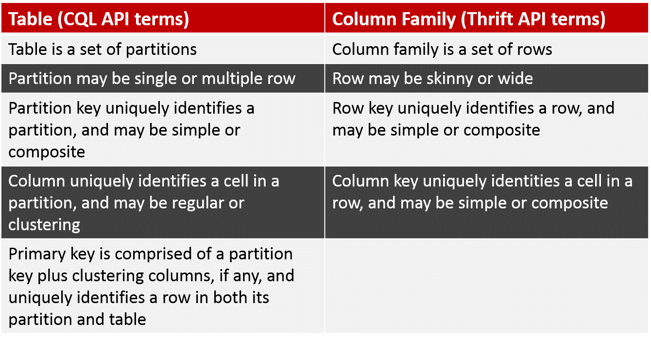
CQL Table and Column Family are largely interchangeable terms supported by Cassandra query language.
Cassandra 1.2+ relies on CQL schema, concepts and terminology. The following table shows the correlation between CQL API and Thrift API terms.
The following figures show examples of CQL table view and Column Family view
CQL Table:
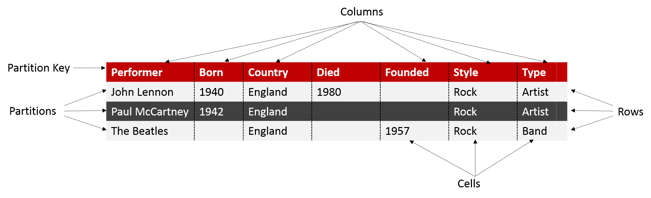
Column Family:

What are the security features available in Cassandra?
- Client-to-Node Encryption: SSL is used to ensure that data is not compromised while transferring between server and client
- Node-to-Node Encryption: Protects data transferred between nodes in a cluster using SSL
- Authentication: Based on internally controlled accounts and passwords
- Object Permission Management: Authorization can be granted or revoked per user to access database objects
Pros and cons
Cassandra is the ideal solution when you need:
- No single point of failure
- Real-time writes with live operational data analysis
- Horizontal scaling across commodity hardware
- Reliable replication across distributed data centers
- Flexible, easily altered data models
It is not ideal when you need ACID Compliance transactions with rollback. Traditional RDMS excel in such scenarios.
Common use cases for Cassandra
Messaging, Fraud Detection, Personalization, Playlists and Collections, Recommendation engines etc.
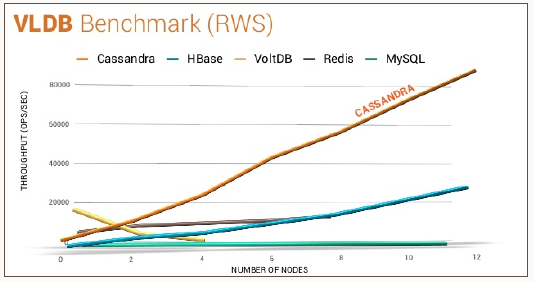
The following chart measuring the scalability and elasticity of distributed database systems shows that Cassandra is highly preferred as compared to other NoSQL databases.
Santosh is a certified Apache Cassandra Administrator and Data Warehousing professional with expertise in various modules of Oracle BI Applications working from KPI Partners Offshore Technology Center. Apart from Oracle, Santosh has worked on Salesforce integration and analytics projects.




Comments
Comments not added yet!